- Home
- Forums
- Discussion topics
- Research quality and methodology discussions
- Other research methodology topics
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Can Large Language Models (LLMs) like ChatGPT be used to produce useful information?
- Thread starter V.R.T.
- Start date
hotblack
Senior Member (Voting Rights)
Wasn’t sure where best to post this or how wide the interest would be so piggybacking on this thread.
While looking at different tools and APIs I’ve increasingly found MCP servers being provided by organisations, for example:
https://www.ebi.ac.uk/ols4/mcp
https://string-db.org/help//mcp/
What is MCP you may ask…
https://en.wikipedia.org/wiki/Model_Context_Protocol
So basically providers of bioinformatics resources are providing ways for LLMs to interact with them (particularly the agentic form of these LLMs) to retrieve information and often do other stuff, like running enrichment analysis or identifying protein interactions.
While looking at different tools and APIs I’ve increasingly found MCP servers being provided by organisations, for example:
https://www.ebi.ac.uk/ols4/mcp
https://string-db.org/help//mcp/
What is MCP you may ask…
https://en.wikipedia.org/wiki/Model_Context_Protocol
So basically providers of bioinformatics resources are providing ways for LLMs to interact with them (particularly the agentic form of these LLMs) to retrieve information and often do other stuff, like running enrichment analysis or identifying protein interactions.
ahimsa
Senior Member (Voting Rights)
Article from Wiki Education:
The article also lists a few areas where chatbots can be helpful.
The article does not mention several of the issues related to chatbots, such as consent (for example, some data used for training was under copyright and should not have been used).
Generative AI and Wikipedia editing: What we learned in 2025
Like many organizations, Wiki Education has grappled with generative AI, its impacts, opportunities, and threats, for several years. As an organization that runs large-scale programs to bring new e…
wikiedu.org
Wiki Edu said:Like many organizations, Wiki Education has grappled with generative AI, its impacts, opportunities, and threats, for several years. As an organization that runs large-scale programs to bring new editors to Wikipedia ... we have deep understanding of what challenges face new content contributors to Wikipedia — and how to support them to successfully edit.
My conclusion is that, at least as of now, generative AI-powered chatbots like ChatGPT should never be used to generate text for Wikipedia; too much of it will simply be unverifiable.
Our staff would spend far more time attempting to verify facts in AI-generated articles than if we’d simply done the research and writing ourselves.
The article also lists a few areas where chatbots can be helpful.
The article does not mention several of the issues related to chatbots, such as consent (for example, some data used for training was under copyright and should not have been used).
ahimsa
Senior Member (Voting Rights)
"Chatbots Make Terrible Doctors, New Study Finds"

 www.404media.co
www.404media.co
This article might be behind a paywall. I'm not sure because I'm a subscriber. I will share a few quotes below.
(line breaks added)
Link to study for folks who want to read more:
 www.nature.com
www.nature.com
Chatbots Make Terrible Doctors, New Study Finds
Chatbots provided incorrect, conflicting medical advice, researchers found: “Despite all the hype, AI just isn't ready to take on the role of the physician.”
www.404media.co
This article might be behind a paywall. I'm not sure because I'm a subscriber. I will share a few quotes below.
(line breaks added)
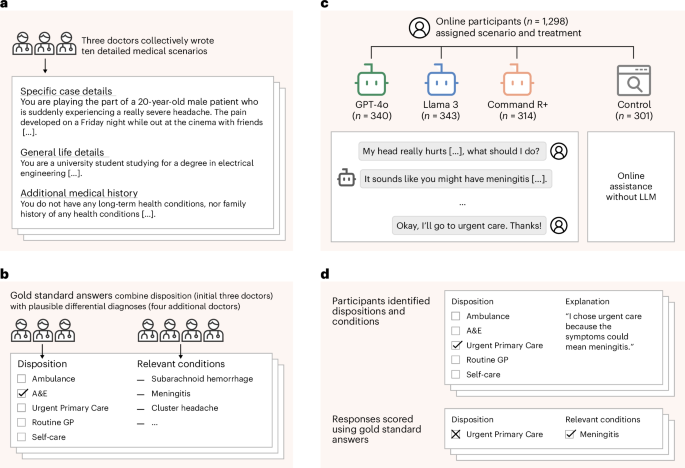
404 Media said:Chatbots may be able to pass medical exams, but that doesn’t mean they make good doctors, according to a new, large-scale study of how people get medical advice from large language models.
The controlled study of 1,298 UK-based participants, published today in Nature Medicine from the Oxford Internet Institute and the Nuffield Department of Primary Care Health Sciences at the University of Oxford, tested whether LLMs could help people identify underlying conditions and suggest useful courses of action, like going to the hospital or seeking treatment.
...
When the researchers tested the LLMs without involving users by providing the models with the full text of each clinical scenario, the models correctly identified conditions in 94.9 percent of cases. But when talking to the participants about those same conditions, the LLMs identified relevant conditions in fewer than 34.5 percent of cases.
People didn’t know what information the chatbots needed, and in some scenarios, the chatbots provided multiple diagnoses and courses of action. Knowing what questions to ask a patient and what information might be withheld or missing during an examination are nuanced skills that make great human physicians; based on this study, chatbots can’t reliably replicate that kind of care.
“In an extreme case, two users sent very similar messages describing symptoms of a subarachnoid hemorrhage but were given opposite advice,” the study’s authors wrote. “One user was told to lie down in a dark room, and the other user was given the correct recommendation to seek emergency care.”
Link to study for folks who want to read more:
Reliability of LLMs as medical assistants for the general public: a randomized preregistered study - Nature Medicine
In a randomized controlled study involving 1,298 participants from a general sample, performance of humans when assisted by a large language model (LLM) was sensibly inferior to that of the LLM alone when assessing ten medical scenarios leading to disease identification and recommendations for...
www.nature.com
I've spent a lifetime working with complex computer systems and new technology.
I spent over 10 years lying horizontal, watching as my pacing kept eroding into smaller and smaller manageable units. I've spent years being schooled by people in these forums and reading an awful lot of research papers. Over the years I've tried just about every supplement, drug or possible solution and thinks just kept getting worse. I was an ME/CFS poster child.
Last fall I used an AI to help diagnose what seemed to me to be a familial muscle problem rather than an ME/CFS problem. I sent my DNA off for full genome sequencing. While I was waiting for results I convinced a GP to prescribe a continuous glucose monitor even though my A1C looked normal. When the glucose results were "spikey" I used to AI to help interpret what was causing the spikes and how to smooth them out.
When the genome sequencing came back I used an AI extensively to help me interpret the results. When the suspected muscle problem emerged I used the AI to look more deeply at the research. Since the muscle condition is officially "harmless" (don't get me started) I looked at research papers from sports physiology to discover there was a standard diet for the muscle condition (CPT2 and AMPD1 deficiencies).
I used the AI to help me understand the nuances of the diet, particularly in relation to activity and glucose levels. i improved and modified with diet with the help of the AI. I am suddenly a functioning human being with a host of problems that simply disappeared.
No doctor has ever said "maybe you're having problems not being able to stand or even sit because you aren't fueling your muscles correctly".
An AI is just another tool. Understanding the tool allowed me to digest and process huge amounts of information very rapidly. In my case, AI was absolutely essential to my recovery.
I spent over 10 years lying horizontal, watching as my pacing kept eroding into smaller and smaller manageable units. I've spent years being schooled by people in these forums and reading an awful lot of research papers. Over the years I've tried just about every supplement, drug or possible solution and thinks just kept getting worse. I was an ME/CFS poster child.
Last fall I used an AI to help diagnose what seemed to me to be a familial muscle problem rather than an ME/CFS problem. I sent my DNA off for full genome sequencing. While I was waiting for results I convinced a GP to prescribe a continuous glucose monitor even though my A1C looked normal. When the glucose results were "spikey" I used to AI to help interpret what was causing the spikes and how to smooth them out.
When the genome sequencing came back I used an AI extensively to help me interpret the results. When the suspected muscle problem emerged I used the AI to look more deeply at the research. Since the muscle condition is officially "harmless" (don't get me started) I looked at research papers from sports physiology to discover there was a standard diet for the muscle condition (CPT2 and AMPD1 deficiencies).
I used the AI to help me understand the nuances of the diet, particularly in relation to activity and glucose levels. i improved and modified with diet with the help of the AI. I am suddenly a functioning human being with a host of problems that simply disappeared.
No doctor has ever said "maybe you're having problems not being able to stand or even sit because you aren't fueling your muscles correctly".
An AI is just another tool. Understanding the tool allowed me to digest and process huge amounts of information very rapidly. In my case, AI was absolutely essential to my recovery.
That's fascinating, @darrellpf. I'd like to understand more of what you found out. I wonder whether you could write up the details of what you found as a case study and get it published. It's possible there may be clues in your genetics and treatment that could move ME/CFS research forward and help others.
MrMagoo
Senior Member (Voting Rights)
At the risk of inviting questions I can’t answer….
(Apologies in advance, at some stage I will produce more info but it’s unlikely to be useful, or scientific, or scaleable etc)
I’ve got so much Fitbit and visible data I can’t manage it so I’ve been feeding it to chat GPT.
So it thinks it can flag some signs that I’m disposed to a crash, etc which is all very interesting but what got me was - it offered to review how many times I’d been in “the stretch zone” as it calls it, but paced and avoided crashing.
Apparently I’m pretty good at pacing, improved a lot last year, avoided a fair few crashes.
It also said I could have avoided some more, but not all because ultimately some would happen anyway and are outside my control.
It might all be BS, but when was the last time you had reassurance that
- you pace really well
- you couldn't have avoided crashing
That’s what was interesting for me.
(Apologies in advance, at some stage I will produce more info but it’s unlikely to be useful, or scientific, or scaleable etc)
I’ve got so much Fitbit and visible data I can’t manage it so I’ve been feeding it to chat GPT.
So it thinks it can flag some signs that I’m disposed to a crash, etc which is all very interesting but what got me was - it offered to review how many times I’d been in “the stretch zone” as it calls it, but paced and avoided crashing.
Apparently I’m pretty good at pacing, improved a lot last year, avoided a fair few crashes.
It also said I could have avoided some more, but not all because ultimately some would happen anyway and are outside my control.
It might all be BS, but when was the last time you had reassurance that
- you pace really well
- you couldn't have avoided crashing
That’s what was interesting for me.
Might be of interest to some:
 www.erdosproblems.com
https://arxiv.org/pdf/2602.05192
www.erdosproblems.com
https://arxiv.org/pdf/2602.05192
https://arxiv.org/pdf/2603.24914
It now seems inevitable that AI will change the world of mathematics, both in education as well research in ways unforeseeable today. I’m still sceptical on whether it can perform the groundbreaking type of “new results” that require something quite novel, but I guess even that is possible to some extent if you have an infinite number of agents acting on an infinite number of agents or similar, all backed by proof verification and to some extent it seems to already be happening. Is that really the point of the exercise? I don’t know.
I doubt it’ll do anything much for ME/CFS in the foreseeable future, given the state of literature, but maybe progress can be made in adjacent fields or perhaps other people that used to be mathematicians, computer scientists or theoretical physicists will turn to becoming medical researchers?
Erdős Problem #1196 - Discussion thread
https://arxiv.org/pdf/2603.24914
It now seems inevitable that AI will change the world of mathematics, both in education as well research in ways unforeseeable today. I’m still sceptical on whether it can perform the groundbreaking type of “new results” that require something quite novel, but I guess even that is possible to some extent if you have an infinite number of agents acting on an infinite number of agents or similar, all backed by proof verification and to some extent it seems to already be happening. Is that really the point of the exercise? I don’t know.
I doubt it’ll do anything much for ME/CFS in the foreseeable future, given the state of literature, but maybe progress can be made in adjacent fields or perhaps other people that used to be mathematicians, computer scientists or theoretical physicists will turn to becoming medical researchers?
Last edited:
There's something @Jonathan Edwards mentioned recently, about how for many problems the data already exist, they are there, making progress is not necessarily dependent on performing totally novel experiments. Maybe I misinterpreted what he said, but the idea applies here. It's very likely that to solve this problem will require novel experiments, probably some new technology, but to make progress, to get the first meaningful steps, probably doesn't require it. There is so much data already out there, enough to work with if what it takes to get a headway is connecting things that people didn't know are connected.It now seems inevitable that AI will change the world of mathematics, both in education as well research in ways unforeseeable today. I’m still sceptical on whether it can perform the groundbreaking type of “new results” that require something quite novel
Most problems like this don't require revolutionary theoretical frameworks, more than anything they require a lot of boring, repetitive work. This, AIs will be able to do. They won't have hands to work with, will have limits to what they can do, but it doesn't seem like it's required here. It probably doesn't involve some organ unknown to science, or looking at things no one thought to look.
Yes, the problem for ME/CFS is of quite a different kind to the ones solved above. You have a large literature of nonsensical results and no means to do algorithmic proof verification, all topped of with a larger bias to publishing experiments with positive results. Which is all exactly the opposite of what grants these approaches success elsewhere.There's something @Jonathan Edwards mentioned recently, about how for many problems the data already exist, they are there, making progress is not necessarily dependent on performing totally novel experiments. Maybe I misinterpreted what he said, but the idea applies here. It's very likely that to solve this problem will require novel experiments, probably some new technology, but to make progress, to get the first meaningful steps, probably doesn't require it. There is so much data already out there, enough to work with if what it takes to get a headway is connecting things that people didn't know are connected.
Most problems like this don't require revolutionary theoretical frameworks, more than anything they require a lot of boring, repetitive work. This, AIs will be able to do. They won't have hands to work with, will have limits to what they can do, but it doesn't seem like it's required here. It probably doesn't involve some organ unknown to science, or looking at things no one thought to look.
You can make some progress by a combination of agents and human interaction for example by filtering through null results rigorously (checking all of the available literature, checking whether multiple corrections were applied, which experiments are hidden in the supplementary materials etc) and in that way rule out all possible things that shouldn’t be involved. That could probably already be very useful but I think at least currently after that step you wouldn’t get much further. Detecting statistical inconsistencies, flagging likely p-hacking, down weighting entire classes of studies etc doesn't seem to be the only crucial part. If you afterwards attempted an automated and literature based hypothesis generation from there on out you’d seemingly have to again base that on nonsensical literature, which can be weighted to some degree, but maybe not quite as it should be. Today one can imagine all sorts of agents with different weighting strategies giving you different hypothesis to check for sensibility and that possibly being helpful to the human trained eye, but you have to ensure those still exist in the first place.
Of course the “learning patterns of when evidence tends to fail” can be automated to some degree, but the way humans do that is not recorded in the literature itself, maybe not to dissimilar to how it isn’t recorded anywhere why Roger Federer as a child had such ease learning how to hit a forehand in comparison to the fellow kids training with him.
Last edited:
Well, researchers are still discovering new organs, and sensing/scanning technology is providing new discoveries practically daily, so there still seems to be plenty of room for ME to involve something previously unknown. It's hard to find an abnormality in something you aren't aware exists.It probably doesn't involve some organ unknown to science, or looking at things no one thought to look.
While true, wouldn't it be possible to train an AI to solve the problem of garbage data? Not easily maybe, but possible. Humans have their own biases and trained perspectives, which might be harder to overcome than for an AI.You have a large literature of nonsensical results and no means to do algorithmic proof verification, all topped of with a larger bias to publishing experiments with positive results. Which is all exactly the opposite of what grants these approaches success elsewhere.
Wouldn't it be nice if someone trained an AI to judge research papers better than humans do?